Im folgenden Bericht erzählt uns Melle etwas über Ihre Abschlussarbeit, wie das Thema entstanden ist und welches Ergebnis erreicht wurde.
Kund:innen erschaffen, die nie existierten – meine Bachelorarbeit über synthetische Daten bei singularIT
Versucht dort gerade jemand mit einem gehackten Kund:innen Konto einzukaufen? Welches Produkt empfehle ich einer Userin noch zum Einkauf des neuen Bestseller Krimis?
Um diese Fragen zu beantworten und bei vielen weiteren Anwendungen zu helfen benötigen Online-Handelsplattformen große Mengen an personenbezogenen Daten. Eines der größten Erfolgsgeheimnisse von Amazon ist die professionelle Nutzung riesiger Mengen dieser persönlichen Einkaufsdaten, zu denen sie als eines der führenden großen Online-Handelsunternehmen fast uneingeschränkten Zugang besitzen. Aber wie ist es mit dem Schutz der Kund:innen bestellt, deren Daten hier verwendet werden? Wie können kleinere Unternehmen mithalten, die nur eingeschränkten Zugang zu solchen Datenmengen besitzen?
Synthetischen E-commerce Daten
In meiner Bachelorarbeit habe ich mich mit einer vielversprechenden Lösung dieser Probleme beschäftigt: dem Erstellen von synthetischen E-commerce Daten. Synthetische Daten spiegeln möglichst viele Eigenschaften und Verbindungen von Original-Datensätzen wieder, sind aber künstliche, neue Daten. Meine Aufgabe war es, mit Hilfe von Methoden aus dem Forschungsbereich der Künstlichen Intelligenz, viele neue synthetische Kund:innen einer Online-Handelsplattform zu erschaffen. Diese Kunden könnte es eventuell geben, existieren aber in Wirklichkeit nicht. Die neuen Kund:innen sind nicht wie bei klassischen Anonymisierungsverfahren mit den alten Kund:innendaten verbunden.
Generative Adversial Networks (GAN)
Besonders im Bereich der täuschend echten Bild- und Videoerschaffung gibt es eine Architektur, die vielversprechende Ergebnisse erzielt hat: die Generative Adversial Networks (GAN). GANs bestehen aus zwei künstlichen neuronalen Netzen, die gegeneinander arbeiten: Eines erschafft künstliche neue Daten (der Generator) und ein zweites ist darauf spezialisiert, immer genauer solche Täuschungen von den Originalen zu unterscheiden (der Discriminator). Durch ein Training von beiden Netzwerken steigt die Qualität der synthetischen Daten, die diese Architektur erschaffen kann.
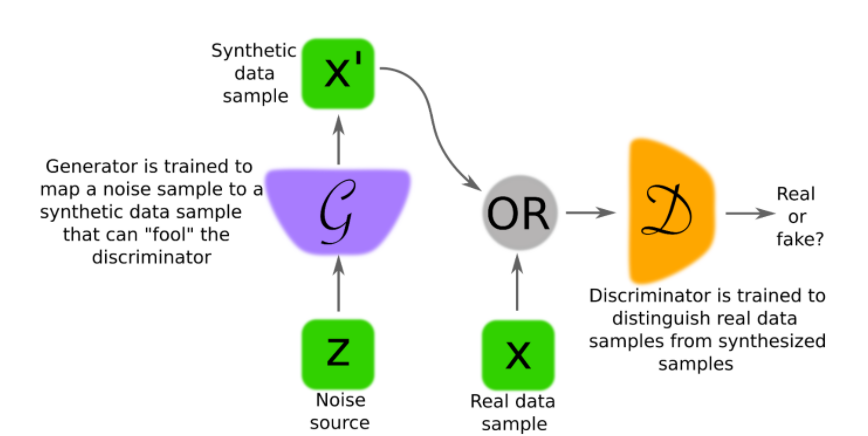
In meiner Bachelorarbeit habe ich mich mit einer Weiterentwicklung der GAN Architektur zur Herstellung von synthetischen Tabellendaten befasst: der Conditional Tabular GAN (CTGAN). Die Synthese von Tabellendaten bringt einige neue Herausforderungen an GAN Architekturen, die bis jetzt vermehrt im Bereich der Bildsynthese eingesetzt werden.
Conditional Tabular GAN (CTGAN)
Im Gegensatz zu Fotodateien, die immer aus Daten desselben Formats bestehen (aus einzelnen Pixeln), besitzt eine Tabelle kategoriale und kontinuierliche Spalten. Kategoriale Spalten, wie Produktkategorien, bestehen aus einer begrenzten Anzahl an Werten. Kontinuierliche Spalten hingegen, wie Kaufpreis, können beliebig viele Werte annehmen. Die CTGAN verarbeitet kategoriale und kontinuierliche Daten mit Hilfe von Vektoren und Funktionsgraphen zu einer Darstellung. Diese kann nun in den künstlichen Neuronalen Netzen verarbeitet werden.
Eine weitere Herausforderung ist eine den Originaldaten ähnliche Verteilung in den synthetischen kategorialen Spalten zu erzeugen. Kategoriale Spalten, wie die oben erwähnten Produktkategorien, bestehen häufig zum Großteil aus einigen Hauptkategorien, wobei andere Kategorien sehr wenig vertreten sind. Zum Beispiel bestellen Menschen in einem Online Buchhandel vermehrt bekannte Bücher und weniger zu bestimmter Literatur angebotenes Merchandising, wie Tassen oder T-Shirts. Trotzdem sollten auch in den synthetischen Daten alle Produkte vorkommen und nicht nur die Bestseller. Um dies zu gewährleisten hat die CTGAN eine eingebaute Bedingung. Diese gibt die eine kategoriale Spalte und darin eine bestimmte Kategorie zur Synthese vor.
Training von CTGAN Modellen
In meiner Bachelorarbeit habe ich unterschiedliche CTGAN Modelle mit einem öffentlich zugänglichen E-commerce Datensatz trainiert. So habe ich eine große Anzahl an künstlichen Kund:innen erschaffen. Als Original-Datensatz habe ich den Superstore Datensatz gewählt. Es handelt sich um einen Datensatz mit Einkaufsdaten aus einem amerikanischen Online-Store für Möbel, Bücher und anderen Haushaltswaren.
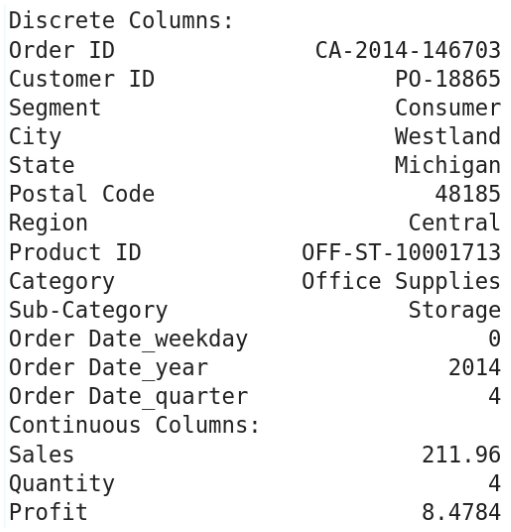
Auf der Webseite zu meiner Bachelorarbeit können synthetische Daten mit der CTGAN erschaffen und ausgewertet werden. Es handelt sich hierbei um Daten vom Superstore Datensatz, einem Supermarkt und medizinische Patient:innen. Diese komplett neuen Datensätze stehen dann zum Download zur Verfügung.
Eine neue Metrik: das CV-Loss
Es gibt zwischen E-commerce Daten viele Beziehungen, die auch in den künstlichen Daten eingehalten werden müssen. Zum Beispiel ist ein Smartphone immer der Kategorie Technologie zuzuordnen und kein Möbelstück. Um diese kategoriale Integrität und die Ähnlichkeit anderer Beziehungen zwischen den Spaltenpaaren zu den Originaldaten zu bewerten, habe ich eine neue Metrik definiert: das CV-Loss. Das CV-Loss basiert auf dem Cramer‘s V, einer statistischen Bewertungsmöglichkeit für Verbindungen von Spaltenpaaren einer Tabelle. Abbildung 3 zeigt alle kategorialen Spaltenpaare des Superstore Datensatzes und die entsprechen Cramer‘s V Werte. Besonders hohe Werte deuten auf einen hohen statistischen Zusammenhang zwischen zwei Spalten hin. Das CV-Loss kann wie das Cramer‘s V Werte von 0 bis 1 einnehmen. Hier gilt aber: umso kleiner das CV-Loss, umso näher liegen die statistischen Beziehungen der original Daten und der synthetischen Daten beieinander.
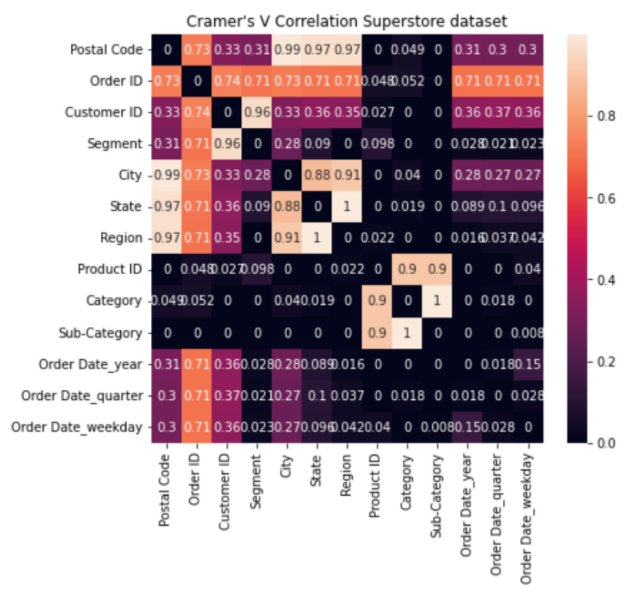
Die Arbeit zeigt, dass die CTGAN Potential zur Generierung von synthetischen E-commerce Daten besitzt. Aktuell weist die Architektur aber noch einige Defizite auf. So werden zum Beispiel nicht alle Beziehungen zwischen den Spalten korrekt in die synthetischen Daten übertragen.
Zusammen mit einem der singularIT-Geschäftsführer, Mattis Hartwig, arbeite ich inzwischen am Deutschen Forschungszentrum für Künstliche Intelligenz. Unser Ziel dabei ist, die CTGAN Architektur weiter zu optimieren.
Du hast auch eine Idee für eine Abschlussarbeit, die du in die Tat umsetzen möchtest? Dann schau dich Hier mal um und schreibe uns eine Mail!